用简单的神经网络预测时间序列
目标
使用过去30天的比特币数据, 1小时K线
目标是用神经网络通过过去24天预测未来1天的走势
模型
名字是LSTM,因为之后要改成LSTM的模型
class LSTM(nn.Module):
def __init__(self):
super(LSTM, self).__init__()
self.fc1 = nn.Linear(LOOK_BEFORE, 30)
self.out = nn.Linear(30, 1)
def forward(self, x):
return self.out(F.relu(self.fc1(x.view(x.size(0), -1))))
这里Linear层要改形状,用 x.view(x.size(0),-1)
Normalization
因为比特币的价格数字很大,必须要这一步,否则无法收敛
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data)
之后使用模型预测的时候,要变换回来
y_pred = scaler.inverse_transform(y_pred)
分割数据集
首先要创建用于训练的数据集,就是输入是24的时间戳,label是下一刻的时间
def make_dataset():
Xs, ys = [], []
for i in range(len(df) - LOOK_BEFORE):
X = data[i:i+LOOK_BEFORE]
y = data[i+LOOK_BEFORE]
Xs.append(X)
ys.append(y)
return Xs, ys
要把数据集分成 train, validation 和 test
split_t = int(0.9 * len(X_dataset))
split_v = int(0.7 * len(X_dataset))
X_train = X_dataset[:split_v]
y_train = y_dataset[:split_v]
X_validation = X_dataset[split_v:split_t]
y_validation = y_dataset[split_v:split_t]
X_test = X_dataset[split_t:]
y_test = y_dataset[split_t:]
效果
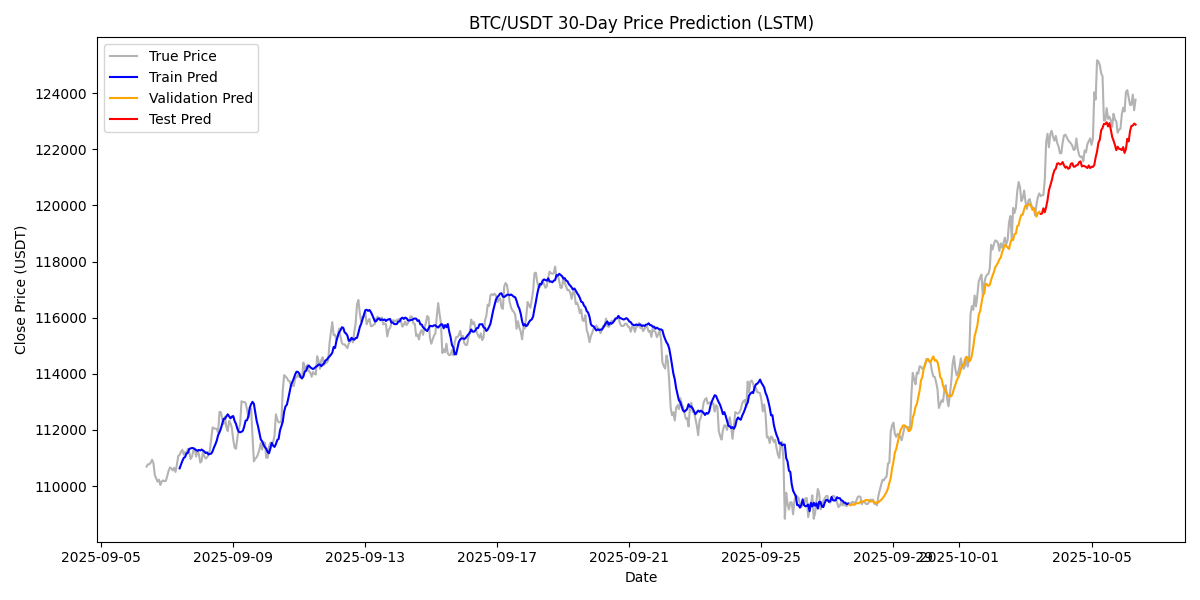
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import pandas as pd
import numpy as np
from torch.utils.data import TensorDataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
df = pd.read_csv('BTCUSDT_30days.csv',index_col='Date', parse_dates=['Date'])
data = df.values
print(df.shape)
LOOK_BEFORE = 24
class LSTM(nn.Module):
def __init__(self):
super(LSTM, self).__init__()
self.fc1 = nn.Linear(LOOK_BEFORE, 30)
self.lstm = nn.LSTM(input_size=1, hidden_size=30, num_layers=2, bias=True, batch_first=True)
self.out = nn.Linear(30, 1)
def forward(self, x):
return self.out(F.relu(self.fc1(x.view(x.size(0), -1))))
model = LSTM()
def make_dataset():
Xs, ys = [], []
for i in range(len(df) - LOOK_BEFORE):
X = data[i:i+LOOK_BEFORE]
y = data[i+LOOK_BEFORE]
Xs.append(X)
ys.append(y)
return Xs, ys
# normalize
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data)
X, y = make_dataset()
X_dataset = torch.tensor(np.array(X), dtype=torch.float32)
y_dataset = torch.tensor(np.array(y), dtype=torch.float32)
print(X_dataset.shape, y_dataset.shape)
split_t = int(0.9 * len(X_dataset))
split_v = int(0.7 * len(X_dataset))
X_train = X_dataset[:split_v]
y_train = y_dataset[:split_v]
X_validation = X_dataset[split_v:split_t]
y_validation = y_dataset[split_v:split_t]
X_test = X_dataset[split_t:]
y_test = y_dataset[split_t:]
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
criterion = nn.L1Loss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
model.train()
total_loss = 0
for X_batch, y_batch in train_loader:
optimizer.zero_grad()
y_pred = model(X_batch)
loss = criterion(y_pred, y_batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}: loss: {total_loss / len(train_loader):.4f}")
model.eval()
with torch.no_grad():
y_val_pred = model(X_validation)
val_loss = criterion(y_val_pred, y_validation)
print(f"Validaition Loss: {val_loss:.4f}")
print("Evaluation on Test set")
model.eval()
with torch.no_grad():
y_test_pred = model(X_test)
test_loss = criterion(y_test_pred, y_test)
print(f"Loss: {test_loss}")
# input -> 30 -> relu -> 1
# 0.04073921591043472
# pure lstm:
# 0.13446228206157684
# lstm + relu
# 0.0469934344291687