Compiler
编译器怎么给变量分配寄存器
C++编译流程
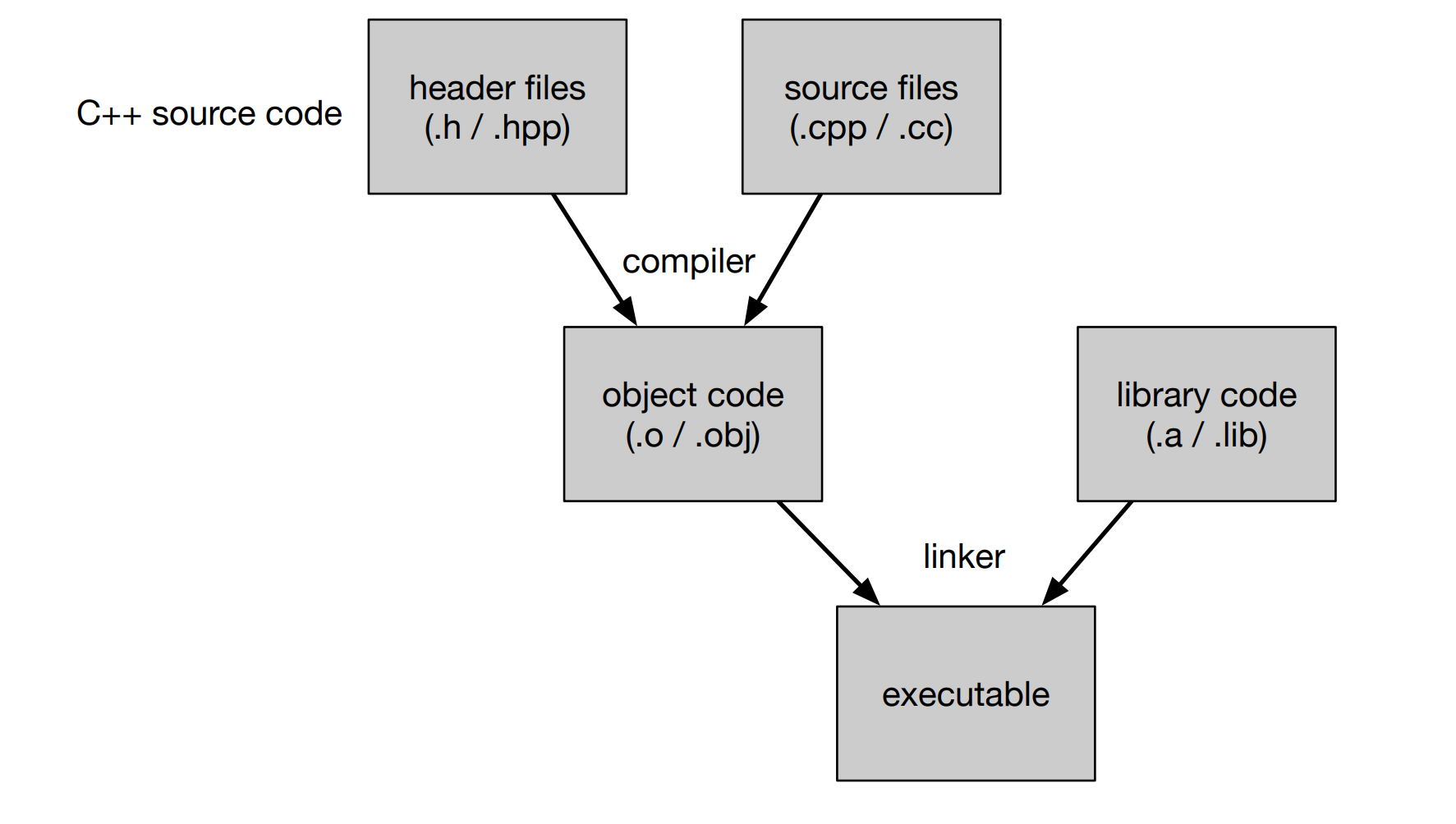
预处理(Preprocessing) → 编译(Compilation) → 汇编(Assembly) → 链接(Linking)
Preprocessing
- 处理所有以
#开头的指令,例如: #include→ 展开头文件;#define→ 宏替换;#ifdef / #ifndef→ 条件编译;- 删除注释;
- 生成纯净的源代码(文本级替换)。
g++ -E main.cpp -o main.i
pragma once
#pragma once 编译器记录该文件的文件路径或 inode(唯一标识);如果再次包含相同文件(即使通过不同路径引用),会直接跳过。不是 C++ 标准语法(属于编译器扩展)但几乎所有现代编译器都支持(GCC、Clang、MSVC、ICC 都支持)
Compilation
g++ -S main.i -o main.s
- 词法分析 (Lexical Analysis):将代码切分成一个个 Token(如关键字、标识符、运算符)。
- 语法分析 (Syntax Analysis):检查语法是否正确,并生成 抽象语法树 (AST)。
- 语义分析 (Semantic Analysis):检查类型匹配、作用域等(例如:不能把字符串赋值给整数)。
- 中间代码生成 (IR Generation):生成一种独立于具体 CPU 架构的代码(如 LLVM IR)。
- 代码优化 (Optimization):根据
-O2或-O3标志进行优化(如删除无用代码、循环展开)。 - 生成汇编代码
Assembly
g++ -c main.s -o main.o
把汇编指令翻译成机器码;
生成符号表(Symbol Table),记录函数和变量的名字及其相对地址。
Linking
g++ main.o other.o -o main
合并段 (Segment Merging)
符号解析(symbol resolution);
地址重定位(relocation);
把外部库函数(如 printf)的引用解析成实际地址;
静态链接 (Static Linking):将库代码(.a / .lib)直接拷贝到可执行文件中。文件较大,但独立性强。
动态链接 (Dynamic Linking):仅记录库的名字(.so / .dll),运行时由操作系统加载。文件小,但依赖环境。
合并多个目标文件生成最终可执行文件。
链接方式
https://hansimov.gitbook.io/csapp/part2/ch07-linking
不是在编译时的 linking 阶段 做的,而是在程序运行时(runtime) 由操作系统的 动态链接器(dynamic linker/loader) 完成的。
在最终可执行文件(ELF)的“动态段”(.dynamic)中,写入:Needed library: libmylib.so
静态链接
把库代码直接复制进可执行文件(如 .a)。在编译过程发生。linux 的连接器是 ld ,做2个工作
- 符号解析symbol resolution:每个符号引用(用了函数)正好和一个符号定义(定义了函数)关联
- 重定位:然后修改所有对这些符号的引用,使得它们指向这个内存位置
符号解析
C++有强符号和弱符号
- 强符号: 一般是有定义的全局函数 / 全局变量
- 弱符号
- 未初始化的全局变量“旧风格”下会被当成 common/弱符号
- 显式标记为
__attribute__((weak))的符号
根据强弱符号的定义,Linux 链接器使用下面的规则来处理多重定义的符号名:
- 规则 1:不允许有多个同名的强符号。
- 规则 2:如果有一个强符号和多个弱符号同名,那么选择强符号。
- 规则 3:如果有多个弱符号同名,那么从这些弱符号中任意选择一个。
重定位
合并同类项:
- 把所有
.text拼成大的.text - 把所有
.data拼成大的.data - 把所有
.bss拼成大的.bss - … 这些“拼起来”的大段,就是将来可执行文件里的段
给它们排“座位”(分配运行时地址):
- 比如:可执行文件里的
.text最终从0x400000开始, - 某个输入文件
a.o的.text占前 0x300 字节, - 下一个
b.o的.text接在 0x300 之后…… - 对
.data、.bss也类似。 - 每个符号的运行时地址 = 所在段的基址 + 段内偏移。
动态链接
implicit linking
程序启动时由系统自动加载动态库.
编译器不会把库内容拷进去,只在可执行文件里写下“依赖信息”。程序运行时再加载共享库(如 .so / .dll)。 当执行 ./app 时:
- 操作系统的动态链接器(Linux 是
ld-linux.so,Windows 是ntdll.dll/kernel32.dll)启动; - 它会去找所需的
.so/.dll文件;动态链接器读取.dynamic区段 - 加载进进程的内存;把库文件
mmap进内存; - 修正符号地址(relocation);
- 如果是 eager binding, 马上进行符号解析(比如找到
foo()的真实地址),填写GOT; - 如果是 lazy binding, 等程序第一次调用的时候解析。
- 然后再跳到
main()执行。
#include <iostream>
#include "mylib.h"
int main() {
foo(); // 函数定义在 libmylib.so 中
}
第一次调用外部函数时,通过 PLT(Procedure Linkage Table)和 GOT(Global Offset Table)间接跳转;
链接器在那一刻查找并缓存地址;
PLT: 用于函数调用的中转表,存储的是:一段间接跳转指令
printf@PLT → GOT[printf] (空) → 调 resolver → 写入真实地址
GOT: 存放外部符号(函数、全局变量)真实地址的表。程序通过读取 GOT 来间接访问外部符号。
explicit linking
程序运行过程中手动加载库
用 dlopen 打开,然后 dlsym 找到函数地址,然后执行
编译选项
fvisibility
-fvisibility=hidden 告诉编译器:默认情况下,所有符号(函数、变量)在共享库中都不导出为可见符号。
Bsymbolic
默认情况下,即使库内部函数之间相互调用,编译器也可能通过 PLT/GOT 调用,在运行时重新解析函数地址。这会造成两个问题:
- 性能损耗(多一次 PLT 跳转)
- 符号冲突风险(库内部函数被外部符号覆盖)
-Bsymbolic 告诉链接器:库内部的符号引用在链接时就绑定,不走运行时重定位。
LTO (Link Time Optimization)
LTO 是“链接时优化”,让编译器在链接阶段对所有目标文件进行整体优化,而不仅仅在编译单个 .cpp 文件时优化。
- 编译器在生成
.o文件时,保留中间表示(IR, Intermediate Representation)
使用方法:
- 编译选项
-flto - 或者CMAKE里
set(CMAKE_INTERPROCEDURAL_OPTIMIZATION TRUE)
Optimization Level
- O0 :不进行任何优化
- O1: 启用基本的优化,保证不显著增加编译时间
- 删除未使用的代码
- 局部变量寄存器分配
- O2: 启用绝大多数安全且通用的优化,不牺牲稳定性。
- 启用循环优化(循环展开、循环不变代码外提);
- 启用内联优化(
inline展开); - 启用指令调度与寄存器重命名
- 启用全局子表达式消除
- O3: 启用更激进的优化,可能导致代码尺寸增大
- 启用更深入的循环展开,Loop peeling
- 启用矢量化(自动 SIMD 优化)vectorization
- 启用函数内联的更高阈值
- 启用更多推测性优化
- Ofast: 极限优化
- 忽略严格的 IEEE 754 浮点运算规则
- 允许编译器假设没有 NaN、没有负零、没有溢出
- 不保证精确的浮点结果或标准兼容性
其他选项
- Os : 启用大多数
-O2的优化,但禁用那些会显著增加代码体积的优化。 - Og: 为调试友好优化
优化方式
Volatile
使用 volatile 关键字可以保证一个变量不被优化。
Loop unrolling
是编译器通过复制循环体内部的代码来减少循环控制开销、提高指令级并行性(ILP)的优化技术。
Loop peeling
循环剥离就是把循环的前几次(或后几次)迭代单独拿出来执行
for (int i = 0; i < n; ++i) {
if (i == 0)
a[i] = 0;
else
a[i] = a[i - 1] + 1;
}
变成
a[0] = 0; // peel out first iteration
for (int i = 1; i < n; ++i)
a[i] = a[i - 1] + 1; // clean loop body, no branching
Loop Fusion
循环融合是把多个循环合并成一个,减少循环开销并提高缓存局部性。
inline
内联(inline)本质上是一种编译期优化建议(hint),而不是命令
| 因素 | 说明 |
|---|---|
| 函数体积 | 太大则不内联(例如超过几十条指令) |
| 递归函数 | 一般不内联(除非尾递归) |
| 函数复杂度 | 有循环、异常、静态变量等 → 不内联 |
| 是否虚函数 | 虚函数调用点通常运行时绑定,无法内联(除非 devirtualized) |
| 是否跨编译单元(跨文件) | 编译器看不到定义就无法内联(除非启用 LTO) |
内联可能反而更慢, 因为
- 增加代码体积
- 造成 instruction cache miss
- 破坏分支预测
Tail Call Optimization, TCO
如果编译器检测到函数是尾递归形式,它可以把“递归调用”优化为“循环跳转”,
int factorial_tail(int n, int acc = 1) {
if (n <= 1) return acc;
return factorial_tail(n - 1, n * acc); // ✅ 尾递归:最后一步就是调用自己
}
编译选项
-march=native根据当前编译机器的 CPU 型号,启用所有本地支持的指令集优化。-fltoLink Time Optimization-funroll-loops尽可能展开循环体(unroll loops)
C++语言特性
编译
lambda
编译期生成匿名类(可调用操作符),处理捕获列表
函数重载
通过命名修饰实现
动态多态
有virtual关键字的时候生成虚函数表
构造的时候插入虚函数表指针
模板实例化
为每个模板实例生成独立的代码
类型推导
auto,decltype 确定变量类型
inline
决定是否为实际内联函数,直接插入函数体
TMP
计算模板元编程
static assert
计算断言
链接
内联变量
一个变量在多个翻译单元有定义,最终可执行文件中只有一个
链接器在链接时,把所有同名弱符号合并为一个
结构体
Structure Layout
结构体的内存布局由成员的排列 + 对齐规则决定。编译器会在成员之间插入padding(填充字节)以满足每个成员的对齐要求
- 每个成员的地址必须是它对齐数的整数倍。
例如
int必须放在 4 的倍数地址上。 - 编译器会自动插入填充字节,保证下一个成员满足对齐。
- 结构体整体大小也要对齐到最大成员的对齐数的整数倍。
- 如果有嵌套结构体,嵌套结构体本身的起始位置也要按其对齐要求对齐。
ABI基础
ABI (Application Binary Interface)是程序在编译后、二进制级别上相互协作的规则。API 是源代码层面(编译前);ABI 是机器码层面(编译后)
Calling Convention
例如在 x86-64 Linux System V ABI 下, rdi, rsi, rdx, rcx, r8, r9 是函数参数, 返回值 rax
Name Mangling
void foo(int);
void foo(double);
C++ 支持函数重载, 如果没有名字修饰,这两个函数的符号都叫 foo,链接器会搞混。编译后
foo(int) → _Z3fooi
foo(double) → _Z3food
Itanium C++ ABI name mangling(GCC、Clang 通用标准)
_Z 是前缀,表示这是一个 C++ 修饰名, 3foo 函数名长度 + 名字, v 是类型 void
禁用名字修饰:
extern "C" void foo(int);
C 语言没有函数重载,不需要 mangling
Object Layout
class A {
int x;
virtual void f();
};
内存布局
[ vptr | x ]
-
vptr:虚表指针(指向类的虚函数表) -
x:成员变量
多态情况:
- 基类子对象在派生类对象的最前面
- 如果有虚函数,每个最左基类放一个 vptr
struct Base { int a; };
struct Derived : Base { double b; };
// 布局: | Base::a (4) | padding (4) | Derived::b (8) |
多继承
struct A { int a; };
struct B { int b; };
struct C : A, B { int c; };
//布局: | A::a | B::b | C::c |
虚继承 (virtual inheritance)
虚继承(virtual inheritance)就是为了解决这个重复继承的问题:此时,C 只会保留 一份 Base。
struct Base {
int x = 10;
};
struct A : virtual Base {};
struct B : virtual Base {};
struct C : A, B {};
/* 内存布局
| A::vbptr | A::a |
| B::vbptr | B::b |
| Base::x |
| C::c | */
vtable
polymorphism 是通过 “虚函数机制” 实现的。当类中有 virtual 函数 时,编译器会
- 给类添加一个隐藏成员指针(称为
vptr,virtual pointer); vptr指向一张虚函数表(vtable);- 表里存储着该类的虚函数的实际地址。
每个对象只存一个指针(vptr),指向它所属类的虚表。vtable 是类级别的共享结构,而 vptr 是对象级别的实例指针。
-fdump-class-hierarchy 加上这个可以输出一个 class 文件, 里面有vtable, g++14后用 -fdump-lang-class
RTTI
RTTI(Run-Time Type Information)是 C++ 提供的一套机制,用于在运行时识别对象的真实类型。即使你通过一个 Base* 指针在操作对象,也可以知道它真正指向的是 Derived
type_info对象, 每个多态类型(即有虚函数的类)都有一个唯一的std::type_info实例- 在虚表(vtable)中,第二项就是指向这个 RTTI 对象的指针。
POD
Plain Old Data (POD = trivial + standard layout)是一种“像 C 一样简单”的类型,它的内存布局与 C struct 相同,没有构造函数、析构函数或虚函数。POD 类型可以安全地被 memcpy、memset、与 C 代码共享内存布局. C++20 起,不推荐再说“POD”,改用:std::is_trivial_v<T>
模板实例化机制
声明阶段(模板定义)
当你写下:
template<typename T>
T add(T a, T b);
编译器只是记录模板的模式,不会生成任何机器码。
当你调用:
int x = add(1, 2); // T=int
double y = add(1.1, 2.2); // T=double
编译器会为每种类型各生成一份“模板实例”
避免重复实例化的机制
模板定义通常放在头文件中
每个 .cpp 引用它时都会看到模板定义。
为防止重复生成代码,编译器使用 “模板实例化合并机制”:
- 每个
.cpp文件中都会可能实例化模板; - 链接器(linker)阶段会去重(COMDAT folding),只保留一份实例化代码。COMDAT(Common Data) 是一种链接器机制, 允许多个目标文件中定义相同符号时,只保留一份副本
零开销抽象(zero-cost abstraction)
使用高级语言特性(如类、模板、智能指针等)时,不会在运行时引入额外性能开销——编译器会在编译期优化掉所有不必要的中间层。What you don’t use, you don’t pay for